




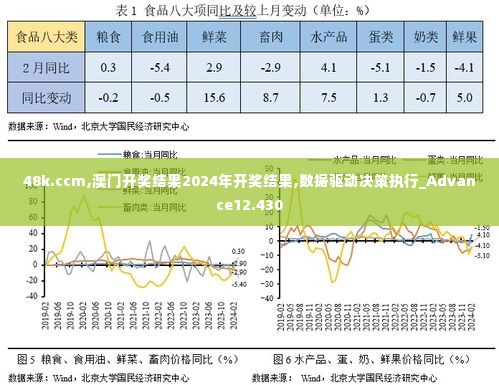

在计算机科学中,遍历文件是一项基础且重要的任务,无论是处理大量数据、编写程序还是进行数据分析,高效遍历文件的能力都是关键,本文将介绍几种高效遍历文件的方法和策略。
为何需要高效遍历文件
文件可能包含大量的数据,如果遍历效率低下,将会导致处理速度缓慢,甚至可能引发性能问题,掌握高效遍历文件的方法和策略对于提高程序性能、节省时间和资源至关重要。
高效遍历文件的方法
1、顺序遍历
顺序遍历是最基本的文件遍历方法,按照文件的顺序,逐个读取文件的每一行或每一个字符,为了提高效率,可以使用缓冲读取和流式处理,以减少IO操作的次数。
2、并行遍历
对于大型文件,可以使用并行处理来提高遍历效率,将文件分割成多个部分,然后在多个线程或进程上同时处理,这种方法可以充分利用多核处理器的优势,显著提高处理速度。
3、索引遍历

对于需要频繁访问的文件,可以创建索引以提高遍历效率,索引是一种数据结构,可以快速地定位到文件中的特定位置,通过索引,可以大大提高文件访问和读取的速度。
提高遍历文件效率的策略
1、选择合适的数据结构
选择合适的数据结构可以显著提高文件遍历的效率,使用哈希表或二叉搜索树等数据结构可以加快查找速度。
2、减少IO操作次数
IO操作是文件遍历中的瓶颈,为了减少IO操作次数,可以使用缓冲读取和流式处理,通过一次性读取大块数据并存储在缓冲区中,可以减少IO操作的次数,从而提高效率。
3、使用高效的文件处理库和工具
使用高效的文件处理库和工具可以大大提高文件遍历的效率,这些库和工具通常具有优化过的算法和高效的实现,可以显著提高文件处理的性能。
实例演示
假设我们需要遍历一个包含大量数据的文本文件,并统计其中每个单词的出现次数,我们可以使用以下步骤来实现高效遍历:
1、使用缓冲读取和流式处理,一次性读取文件的多个行或字符;
2、使用并行处理,将文件分割成多个部分,并在多个线程上同时处理;
3、使用哈希表作为数据结构,记录每个单词的出现次数;
4、使用高效的文件处理库和工具,如Python的collections模块或Java的HashMap类;
5、合并各个线程的结果,得到最终的统计结果。
高效遍历文件对于提高程序性能、节省时间和资源至关重要,通过选择适当的方法和策略,如顺序遍历、并行遍历、索引遍历以及选择合适的数据结构、减少IO操作次数和使用高效的文件处理库和工具等,我们可以显著提高文件遍历的效率。
转载请注明来自天津锦麟商贸有限公司,本文标题:《高效文件遍历方法与策略指南》




 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...